用網頁爬蟲時,網站通常會有一些機制來阻止大量的自動化請求,保護伺服器資源。
因此,瞭解如何避開這些防爬蟲機制是我們在開發爬蟲時不可忽視的課題。
當我們開發爬蟲時,理應尊重網站上的 robots.txt 文件,它主要用來告訴爬蟲哪些頁面是可以爬取的,哪些頁面是禁止爬取的。
舉例來說,當我們訪問一個網站時,可以通過 https://www.google.com/robots.txt 來查看該網站的爬蟲規則。這些規則包含 "Disallow" 和 "Allow" 指令,用來告訴爬蟲哪個路徑可以被爬取,哪個不行。
可以看到google有明確的規範哪些可以爬,哪些禁止: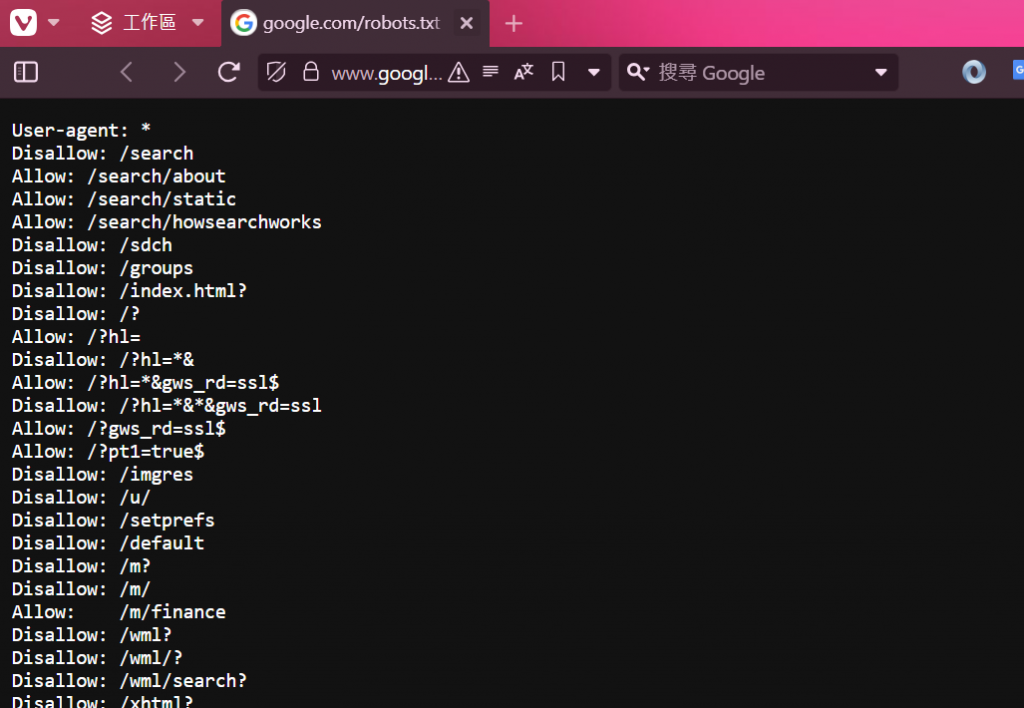
接著再看一下我們的目標 591
https://rent.591.com.tw/robots.txt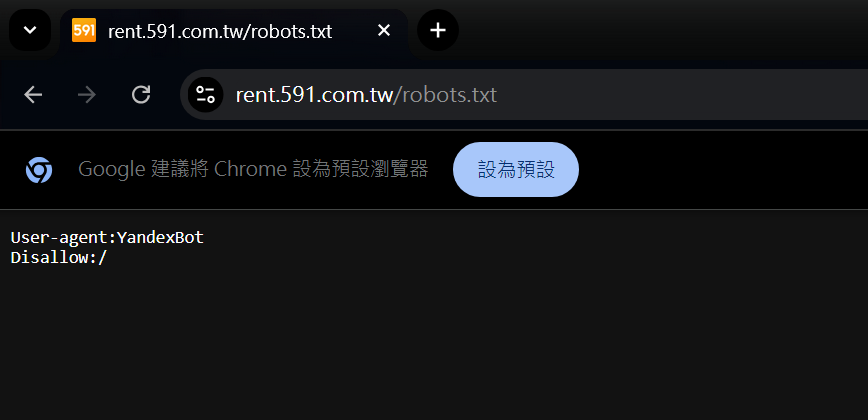
可以看到591並沒有明確的規定,但也不代表我們可以隨意的爬取591的資料,造成他們伺服器的負擔。
大多數網站都不會完全依賴 robots.txt 來防止爬蟲,它們會採取更強大的防爬措施,以限制高頻的自動化請求。常見的防爬措施包括:
頻率限制(Rate Limiting)及 IP 封鎖: 當爬蟲以過高的頻率發送請求時,網站會設定一個限制,超過這個限制的請求將被暫時或永久封鎖 IP 地址。這是許多網站採用的一種常見且有效的防禦方式。
驗證碼(CAPTCHA): 網站可以通過驗證碼來確認請求是否來自於真人操作,而不是自動化程式。驗證碼的應用對爬蟲來說是很大的阻礙。
User-Agent 檢測: 網站可以根據請求中所帶的 User-Agent 字串來判斷請求的來源。如果網站發現大量異常的 User-Agent,例如標示爬蟲工具或過於單一的模式,可能會進行封鎖。
Cookie 和 Session 驗證: 有些網站會檢查用戶的 Session 或 Cookie,確保訪問是來自有效的使用者行為。
網站可以通過監控來自不同 IP 的流量,當檢測到某個 IP 短時間內發送了過多的請求,或者以不尋常的模式進行瀏覽,網站就可能暫時或永久封鎖這個 IP。
IP 封鎖的實作原理通常涉及以下幾種方式:
基於頻率的封鎖: 這是最直接的方式,當同一個 IP 短時間內發出過多的請求時,系統會認為這個 IP 是一個惡意爬蟲,進而封鎖它的訪問。
基於區域的封鎖: 某些網站會根據地理位置來封鎖特定區域的 IP,這通常是因為這些區域的網絡流量被認為有較高的風險。
使用防火牆過濾: 網站可以使用 Web 應用防火牆來篩選和封鎖來自可疑 IP 的請求。
雖然網站有各種方法來封鎖爬蟲,但我們也有一些策略來避免被封鎖。以下是幾種常用的技巧:
切換 User-Agent: 每個瀏覽器和裝置都會發送一個 User-Agent 標頭來表明請求來自哪種設備或軟件。我們可以在爬蟲中隨機切換 User-Agent,讓網站難以檢測出我們是爬蟲。
模擬人類行為: 在每次請求之間加入隨機的延遲,模擬人類瀏覽網頁的行為,避免高頻率的請求。
IP 代理: 使用代理來切換請求的 IP,這樣即便某個 IP 被封鎖,爬蟲還可以繼續使用其他代理 IP 繼續工作。
處理驗證碼: 有些自動化工具能夠處理簡單的驗證碼,但如果遇到更高級的驗證機制,可能需要手動介入。
代理服務(Proxy) 是一種經常被用來繞過 IP 封鎖的技術。代理服務允許我們將請求發送到一個中介伺服器,該伺服器再將請求轉發給目標網站。這樣的話,我們的真實 IP 不會暴露,並且可以根據需要更換代理伺服器。
以下是兩個免費的代理服務平台:
明天我會實作如何爬取FreeProxyList的資料,讓我們的租屋通知機器人使用。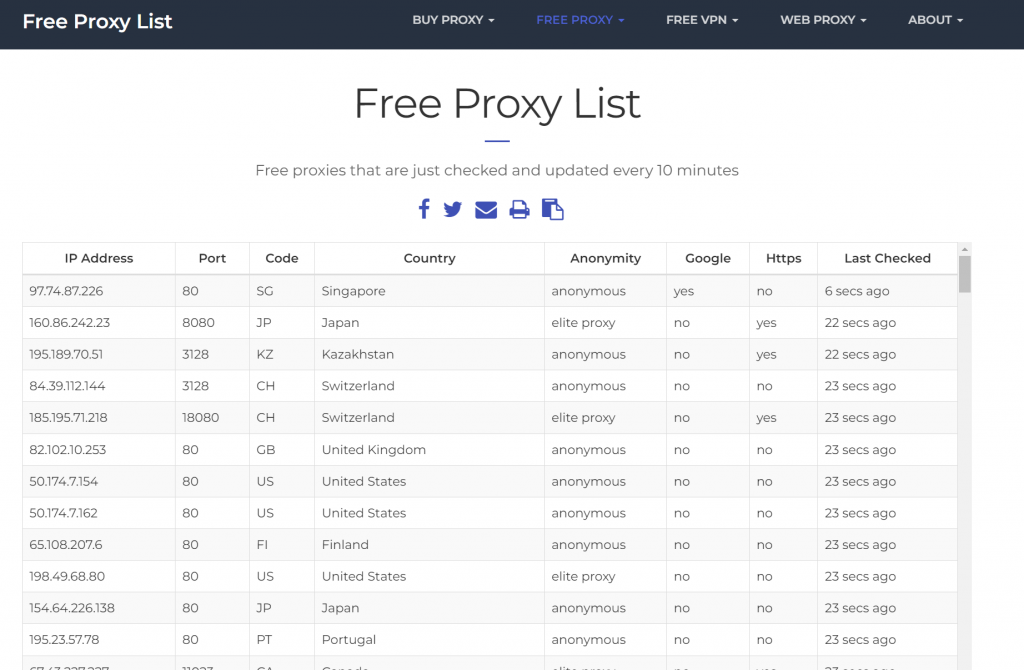
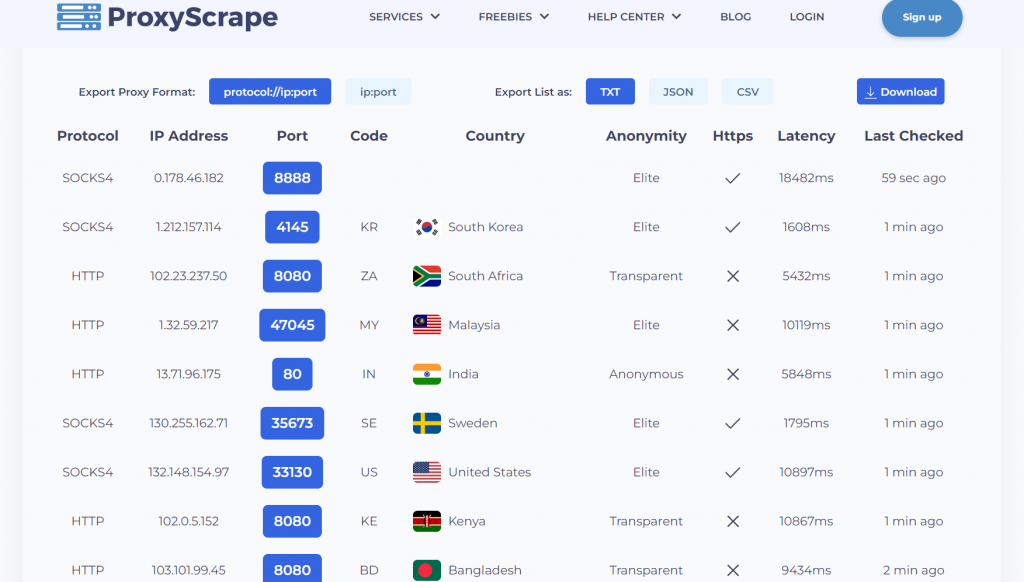
今天我們探討了網站如何使用 robots.txt、頻率限制以及 IP 封鎖來防止爬蟲,並介紹了如何通過更換代理 IP 來避免被封鎖。
明天我們將進行實作,爬取免費的 Proxy 資料,並將這些代理整合到我們的租屋通知機器人(Discord Bot)中,使爬蟲更加智能化且難以被封鎖。


 iThome鐵人賽
iThome鐵人賽